
 (8 votes, moyenne: 4,50 sur 5)
(8 votes, moyenne: 4,50 sur 5)De nombreux projets de sciences de données utilisent la méthodologie CRISP-DM qui est connue et bien établie comme standard de facto depuis 2003. En revanche, la CRISP-DM a des limitations surtout en ce qui concerne la compréhension et le déploiement métier. Aujourd’hui, le processus de modélisation de la décision et le graphique de l’arbre de décision répondent à ces défis.
La CRISP-DM est populaire mais avec des limitations
La CRISP-DM est toujours la méthodologie la plus populaire pour les analyses, le data mining et les projets de sciences de données selon le blog KDnuggets. Cependant la CRISP-DM ne répond pas à toutes les contraintes des projets data science et une autre alternative est attendue depuis longtemps.
Les 6 étapes de la méthodologie CRISP-DM représentent toujours une bonne description pour le processus d’analyse, par contre les détails et les besoins spécifiques doivent être mis à jour. Concrètement, CRISP-DM n’est pas adapté aux défis actuels du Big Data et de la science des données, parce que nouveaux besoin sont apparus comme le stream processing et le real time processing.
Les data scientists reconnaissent qu’une collaboration avec des partenaires métier est essentielle pour offrir une valeur business. Ils ont également reconnu que de nombreux modèles d’analyse ne sont pas déployés ou ne fournissent pas la valeur business attendue. Les data scientists adoptent ce qu’on appelle la modélisation des décisions pour remédier à ces lacunes.
Une compréhension des business partagée
La CRISP-DM et d’autres méthodes soulignent l’importance de la compréhension business, mais n’ont pas de format compréhensible. La modélisation des décisions comble cette lacune.
C’est une technique réussie qui développe une compréhension de business de façon plus riche et plus complète. En utilisant le Modèle de Décision et de Notation (MDN), cette méthodologie résulte d’un objectif business clair, ainsi qu’une compréhension de la manière dont les résultats seront utilisés et déployés et par qui.
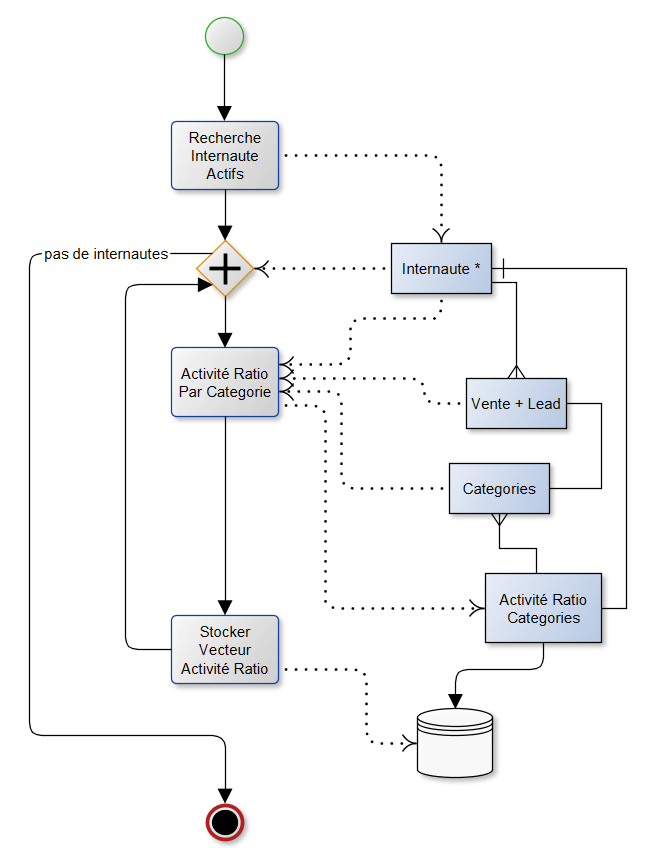
Figure 1 : Exemple de graphique d’arbre de décision
Cette figure représente un exemple de modélisation de décision graphique afin d’augmenter les internautes actifs sur le site du client comme objectif métier global. Cet objectif est atteint par plusieurs exigences. Chacune de ces exigences a ses propres sources de données et par conséquent, des techniques différentes pour l’analyse.
Les équipes de sciences des données signalent d’énormes avantages en établissant rapidement une compréhension partagée avec leurs partenaires business. Les partenaires business ont une vision beaucoup plus claire de ce que le modèle prédictif pourrait faire et de la manière dont il peut être amélioré.
La collaboration entre les data scientists et les équipes métier est un processus itératif. Au fur et à mesure, cela conduit à tirer des informations plus intéressantes et utiles pour le choix du modèle. Cela clarifie également pour l’équipe de science des données quel modèle serait le plus approprié pour le problème business abordé, et il est souvent différent de ce qui était initialement considéré.
Plan de déploiement
De nombreux résultats analytiques ne sont pas déployés car le contexte de déploiement n’a pas été entièrement compris et articulé. Il en résulte des modèles analytiques qui peuvent être techniquement corrects, mais ne résolvent pas le problème métier, ou ne peuvent pas être déployés pour des raisons systémiques, organisationnelles ou encore à cause du processus métier lui-même.
L’écart de déploiement est l’une des raisons pour lesquelles de nombreux dirigeants demandent : « Comment puis-je obtenir de la valeur de mes investissements d’analyses ? ». Les équipes de sciences des données demandent également : « Comment démontrer la valeur de nos résultats analytiques? ».
La prise en compte du contexte décisionnel est fondamentale pour la modélisation des décisions et sert également à définir et planifier le déploiement. Les modèles d’exigences de décision garantissent que les exigences de déploiement et d’utilisation sont claires avant que les analyses ne soient développées. Ils montrent également comment les analyses vont ajouter de la valeur et générer un impact business permettant de développer des business cases et des projets à comparer.
La modélisation de décision améliore CRISP-DM
En conclusion, la modélisation de décision avec la MDN est une technique simple qui améliore la CRISP-DM, répondant aux défis clés pour les équipes de data mining en termes de compréhension et déploiement du business. Les équipes de data science signalent des avantages rapides issus de la modélisation de la décision en se focalisant sur le cœur du projet et la résolution des problèmes de construction de modèles machine learning, trop difficiles à penser.
En ce moment, j’applique la modélisation de décision, la CRISP-DM et d’autres méthodologies dans mes projets clients de data mining. Si vous avez besoin d’un conseil pour le choix de la stratégie la plus approprié du process model pour l’analyse de vos data en fonction de vos contraintes métier, je pourrai vous apporter une réponse. Contactez-nous !







