
Les pratiques de
développement agile laissent souvent de côté le
développement de la base de données ou, pour être plus précis, le
développement SQL. Ce constat n’est pas nouveau car, même avant l’émergence des
méthodes agiles, le
développement SQL était vu comme « différent » (pour ne pas dire autre chose) du développement des autres composants
d’une architecture logicielle.
Cet article n’a pas pour but d’identifier les raisons de cette « différence » perçue mais de tenter de répondre à un problème
concret qui est d’inclure dans le processus cyclique d’intégration continue les artefacts de
développement SQL et, par extension, la base de données.
En règle générale un
projet de développement d’application d’entreprise s’organise autour d’une équipe de
développement Java (ou
.NET) qui fonctionne en mode agile et met en œuvre les principes d’intégration continue. Sauf en qui concerne le
développement qu’implique la persistance des données. Une seule personne qui possède le titre pompeux de
DBA du projet fait office de
développeur SQL,
de gestionnaire d’environnement et pour tout dire, de goulet d’étranglement officieux du projet. Pour illustrer mon propos,
je vous livre une petite anecdote sous forme d’un dialogue très peu fictif.
Chef de projet : « Nous avons besoin d’un nouvel environnement d’UAT pour dans trois jours. Peux-tu t’occuper de
monter une base Oracle disposant de la dernière version des schémas ? »
DBA : « Pas de problème. »
Développeur Java : « Il y a un souci avec cette requête, j’aurais besoin que tu y regardes. C’est trop lent. Je
pense que j’ai fait une bêtise en l’écrivant. Le résultat est juste mais ça devrait aller plus vite. »
DBA
: « Oui, j’y jetterai un œil. »
Architecte : « Nous avons constaté un accroissement du temps de réponse moyen pour les requêtes du composant Untel
lors de notre dernière campagne de tests de performance. Voici les rapports de ton confrère DBA du site de test. Vérifie-les
et propose-moi tes propres recommandations. »
DBA : « Aucun souci. »
Parmi des trois tâches proposées à notre très peu fictif
DBA, une seule est réellement de sa compétence. Si vous avez trouvé laquelle, la suite de cet article vous éclairera
sur la stratégie à appliquer pour laisser ce
DBA se concentrer sur cette tâche. Dans le cas contraire, proposez au
DBA de votre propre projet de lire cette anecdote et écoutez sa réponse.
Un bref rappel de ce que recouvre cette notion d’
intégration continue est cependant nécessaire pour nos lecteurs qui ne sont pas familiers avec le sujet.
L’intégration continue
L’
intégration continue (
IC) répond au problème de l’estimation de la qualité du logiciel produit en apportant comme solutions, premièrement,
l’ajout fréquent et régulier des changements de code à une version de référence commune à tous les développeurs et, deuxièmement,
l’automatisation de la construction des versions et des tests.
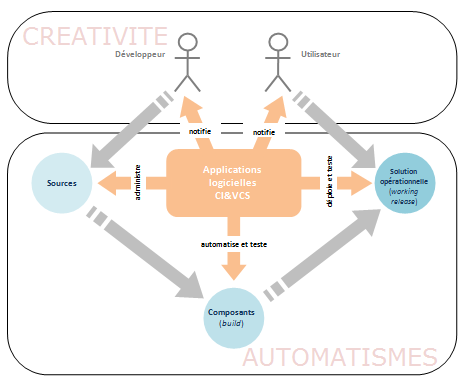
Ces principes imposent deux conditions :
- le retour arrière vers une version stable doit toujours être possible en cours d’intégration
- chaque nouvelle itération doit démarrer avec une version initiale (qui est vide dans le cas d’un nouveau projet)
Cette liste de conditions n’est bien sûr pas exhaustive. En revanche ces deux conditions sont également deux des contraintes
les plus fortes lorsqu’il s’agit d’appliquer les principes de l’IC au
développement SQL.
Un système effectivement transactionnel
En première analyse, ces deux conditions sont respectées par tout système transactionnel dont les transactions sont journalisées
ce qui le cas des
SGBDR qui méritent leur nom. Cependant, en pratique, on observe que, d’une part, le côté statique des schémas de
base de données relationnelles et, d’autre part, la difficulté à obtenir une image précise du passé d’une base
de données empêchent ces conditions d’être remplies rendant ainsi stériles les efforts d’intégration continue.
De plus, si la construction automatique des fichiers sources repose sur le principe d’une routine de rechercher/remplacer/compiler
effectuée pour chaque fichier source dans n’importe quel ordre grâce à la détection automatique des dépendances par les
compilateurs et les outils d’injection de dépendances, la construction d’une base de données à partir de
scripts SQL implique que ces scripts soient exécutés dans un ordre strict pour éviter les erreurs sans qu’il soit
pratiquement faisable de calculer cet ordre automatiquement.
Et pourtant…
Nous avons identifié d’autres circonstances qui, selon nous, constitue des freins encore plus importants à l’adoption des
pratiques d’IC dans le cas du
développement SQL.
- les opérations d’
application de script SQL, de migration et d’initialisation de version sont le plus souvent manuelles donc sensibles
aux erreurs et coûteuses en temps - il existe un manque d’outil ou, au contraire, une pléthore d’outils trop diversifiés pour la détection des changements entre
deux versions. Ces outils s’intègrent assez mal aux logiciels d’administration de l’IC (Hudson par exemple) - d’une manière générale, il n’existe pas de méthode simple et transparente pour affecter un numéro de version à un schéma
de base de données ou à un objet de schéma.
A tout ceci s’ajoute le fait que les dépendances entre la logique applicative et la logique de persistance sont fortes, déstructurées
et disséminées que l’
architecture intègre un ORM ou non.
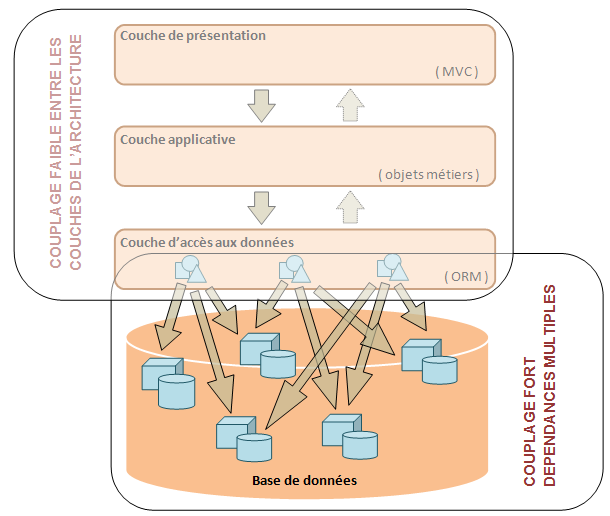
Même s’il ne s’agit pas du sujet principal de l’article, nous ne pouvons que constater le retour de ce vieil ami qu’est le
problème de « l’adaptation d’impédance objet-relationnel » (Object-relational impedance mismatch). Est-ce que les techniques
habituelles de résolutions de ce problème bien connu permettent aussi de lever les freins à l’adoption des pratiques de
l’Intégration Continue ?
Il en est une, en effet, qui nous paraît prometteuse dans ce contexte. Il s’agit de la mise en œuvre d’une architecture alternative
basée sur des
services de base de données. Avec l’émergence des bases de données XML (ou JSON, ne soyons pas sectaires), les
formats d’échange entre la couche de persistance (la base de données) et la couche d’accès aux données (l’ORM dans la plupart
des cas) peuvent voir leur couplage et leur interdépendance réduits.

Est-ce suffisant pour que la pratique de l’Intégration Continue soit adoptée par les développeurs de base de données ? Nous
serions tentés de répondre oui mais la réduction du couplage n’est qu’un pré-requis et il en existe d’autres. Avant de parler
d’outillage et de suites logicielles d’ALM (Application Lifecycle Management), il convient de respecter les principes établis
plus haut. A savoir et en premier lieu, être capable de considérer les scripts SQL qui créent et modifient les objets de
la base de données au même titre que le reste du code source applicatif. Pour atteindre cet objectif, la détection automatique
des changements, l’affectation automatique d’un numéro de version à un état de la base, la construction automatique de la
base de données et de son contenu (structures et données), les tests automatiques et la réversion doivent donc devenir des
réalités. Afin d’éviter l’écriture d’un billet long et fastidieux, j’envisage d’aborder chacun de ces points dans une série
d’articles à venir et d’y apporter des solutions dans le cadre de l’utilisation d’Oracle Database Server 11g, ou de PostgreSQL
9. Pour l’heure, l’application des principes de l’
Intégration Continue au processus de
développement SQL pourrait produire ceci :
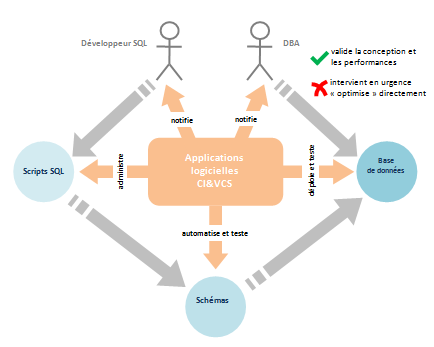
Comme l’indique le schéma, un effet de bord bénéfique de cette approche est de libérer le
DBA du projet des tâches ancillaires de préparation manuelles des environnements, de logistique des données et
de tests unitaires à la volée des
requêtes SQL pour qu’il se concentre sur les travaux à haute valeur ajoutée que sont la validation formelle des
schémas et le diagnostic de performance.
Consultez également :
- le
success storys de nos clients.
la stratégie business de la SSII Pentalog.- nos
équipes des développeurs
l’offre des experts : conseil, audit, ergonomie IT








